The Agentic SRE - Shifting Level 1 Support to AI
In modern platform engineering, the bottleneck is rarely the technology itself. It is the human time required to triage repetitive infrastructure tickets. When a developer opens a ticket for a crashing pod or a latency spike, they often wait hours for an initial response.
This article details a solution built on Google Cloud that shifts these Level 1 diagnostics to an AI Agent. By automating the first layer of analysis, we reduce Turnaround Time (TAT) from hours to seconds and free up the platform team for high-value architectural work.
The Shift-Left Strategy: Immediate 1st Resolution
Shift-left is the practice of moving operational tasks earlier in the lifecycle. In this context, it means providing an expert-level diagnostic report the moment a ticket is created.
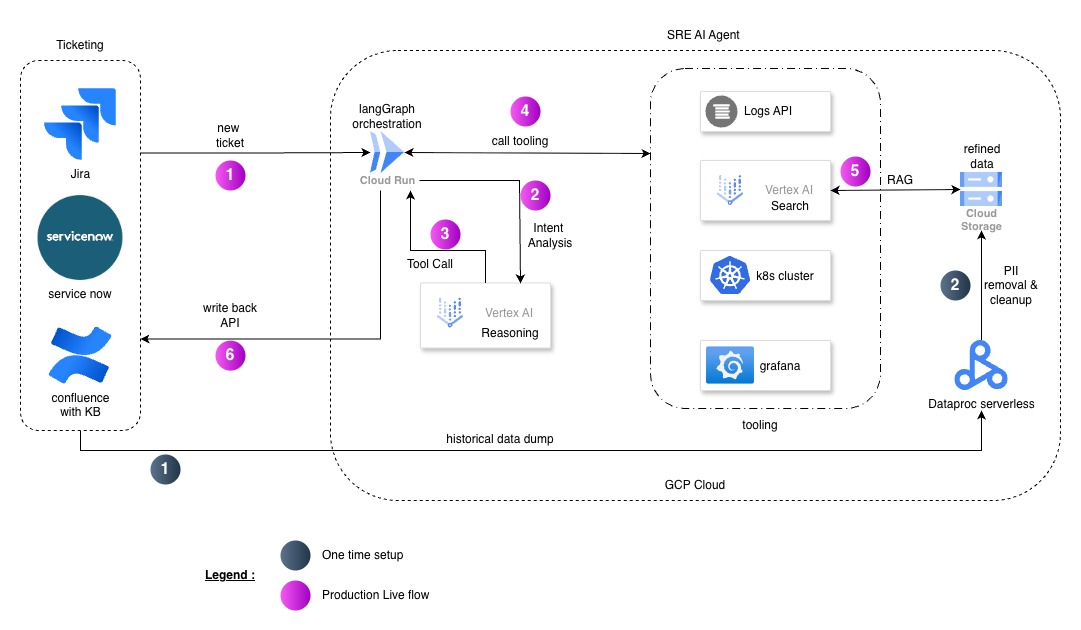
Instead of a human SRE manually running commands, our agent acts as the first responder:
Instant Triage: The agent acknowledges the ticket immediately, providing an initial Root Cause Analysis (RCA).
Reduced TAT: Developers get actionable feedback (e.g., “Your service is OOMKilled; increase memory limits to 2Gi”) without waiting for an SRE shift to begin.
Toil Reduction: Known issues like image pull errors or resource exhaustion are resolved or explained by the AI, leaving only complex “Black Swan” events for the platform team.
Architecture: Why Kubernetes and Serverless?
Kubernetes (K8s) is the backbone of most of the solutions these days because of its standardized observability. In 2026, K8s is the global standard for AI workloads due to its robust APIs for logs and metrics, so it becomes the primary data sources for our agent’s reasoning.
We chose a serverless execution model using Cloud Run for several reasons:
Cost Efficiency: There are no idle servers. You pay only for the seconds the agent is actually analyzing a ticket.
Scaling: If a global outage triggers a “ticket storm,” Cloud Run scales instantly to handle hundreds of concurrent triage requests.
Security: Each agent run uses a managed Service Account with granular, read-only access to your GKE clusters.
Closing the Loop: Automated Knowledge Feedback
A static agent eventually becomes outdated. To prevent this, we built a self-learning loop:
Confluence Preparation: For every ticket resolved, the agent summarizes the fix into a structured Markdown document.
Dataproc Refinement: A Dataproc Serverless job runs daily to clean these documents, remove sensitive PII, and convert them into a format optimized for RAG.
Knowledge Injection: This refined data is fed back into Vertex AI Search, ensuring the agent learns from every new incident.
Effectiveness: When It Works and When It Fails
No solution is a silver bullet. It is critical to understand the boundaries of agentic SRE.
Effective Scenarios:
Known Failure Patterns: Excellent at identifying OOMKills, CrashLoopBackOffs, and standard latency spikes.
Scale-Out Teams: Ideal for large organizations where multiple teams share a single platform group.
High Volume, Low Complexity: When 70% of tickets are “low-hanging fruit” that waste human time.
Where It Goes for a Toss:
Novel Architectures: If you just migrated to a new technology, the agent will lack the historical RAG context to be helpful.
Silent Failures: Issues like logical bugs in business code that don’t trigger infrastructure alerts are still best handled by humans.
Broken Data Pipelines: If your logging or monitoring agents fail, the SRE agent is “blind” and can produce hallucinations.
Conclusion
By leveraging the Vertex AI Reasoning Engine and Cloud Run, platform teams can finally break the cycle of repetitive firefighting. This architecture doesn’t replace the SRE; it elevates them to the role of the architect, while the agent handles the grind of the 2:00 AM ticket.
Share with others on